আপনারা হয়তো এক্সে (X) “Gemini 4” ট্রেন্ডিং হতে দেখেছেন। কিন্তু গুগল আসলে যা রিলিজ করেছে তা হলো Gemma 4, যা জেমিনি ফ্যামিলির একটি ওপেন-ওয়েটস (open-weights) সংস্করণ। যারা কম্পিউটার ভিশন ইঞ্জিনিয়ার, তাদের জন্য এই ওপেন মডেলটি প্রোপাইটারি মডেলের চেয়ে অনেক বেশি গুরুত্বপূর্ণ হতে পারে।
এর পেছনে বেশ কিছু কারণ রয়েছে। Gemma 4 রিলিজ হয়েছে Apache 2.0 লাইসেন্সের অধীনে (গেমা সিরিজে এটিই প্রথম)। এতে রয়েছে নেটিভ বাউন্ডিং বক্স আউটপুট, কনফিগারেবল ইমেজ টোকেন বাজেট এবং একটি এজ (edge) ভেরিয়েন্ট, যা Raspberry Pi 5-এ প্রতি সেকেন্ডে ৭.৬ টোকেন জেনারেট করতে পারে। এর চারটি মডেল সাইজই ইনপুট হিসেবে ছবি এবং ভিডিও গ্রহণ করতে পারে। সবচেয়ে ছোট মডেলটি ১.৫ জিবির (GB) চেয়েও কম র্যামে চালানো সম্ভব।
এই ব্লগে আমরা আলোচনা করব গুগল ঠিক কী রিলিজ করেছে, ভিশন টাস্কের ক্ষেত্রে এর আর্কিটেকচার কীভাবে কাজ করে, কোন বেঞ্চমার্কগুলো আপনার জানা প্রয়োজন, এজ ডিপ্লয়মেন্টের খুঁটিনাটি এবং Qwen 3.5 ও Llama 4 Scout-এর তুলনায় Gemma 4 এর অবস্থান আসলে কোথায়। আপনি যদি গুগলের আগের ভিশন মডেল (যেমন PaliGemma) নিয়ে কাজ করে থাকেন, তবে ডিভাইসের ভেতরে ওপেন-ওয়েটস মাল্টিমোডাল মডেল কী করতে পারে, সেই ক্ষেত্রে Gemma 4 একটি বিশাল অগ্রগতি।
The Gemma 4 Model Family
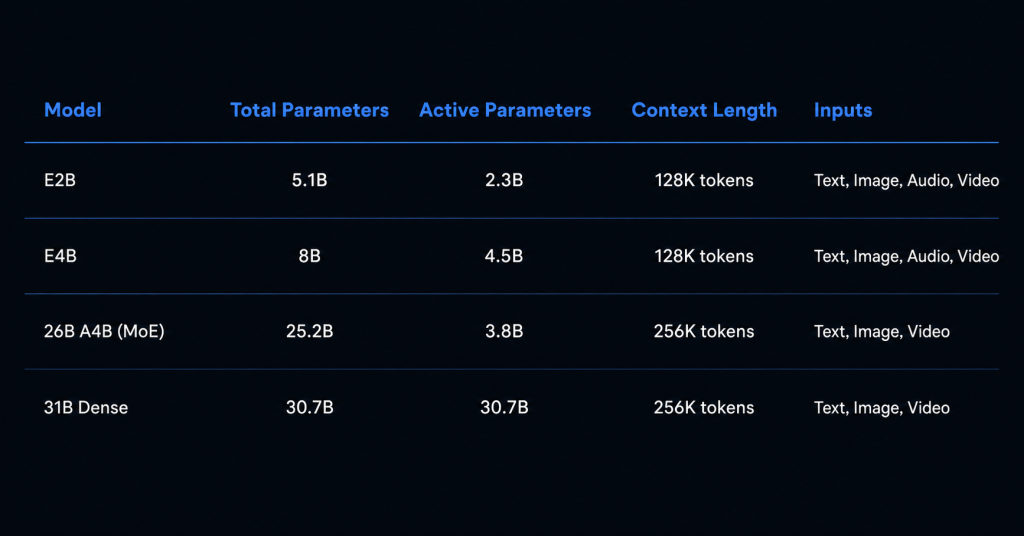
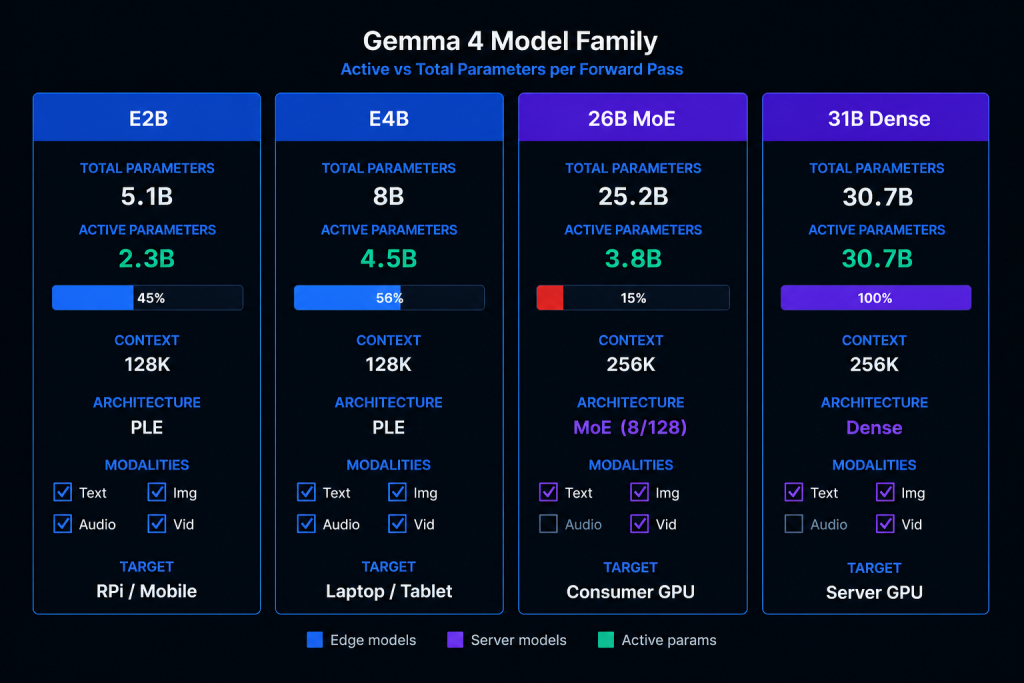
গুগল ২ এপ্রিল, ২০২৬-এ Gemma 4-এর চারটি ভেরিয়েন্ট রিলিজ করেছে। এর মধ্যে 31B হলো একমাত্র সম্পূর্ণ ডেন্স (dense) মডেল (প্রতিটি ফরোয়ার্ড পাসে এর ৩০.৭ বিলিয়ন প্যারামিটারই সক্রিয় থাকে)। 26B মডেলটি মিক্সচার-অফ-এক্সপার্টস (MoE) রাউটিং ব্যবহার করে, যা প্রতি টোকেনে ১২৮টি এক্সপার্টের মধ্যে মাত্র ৮টিকে সক্রিয় করে। তুলনামূলক ছোট দুটি মডেল (E2B এবং E4B) কম্পিউট কমানোর জন্য পার-লেয়ার এম্বেডিংস (PLE) ব্যবহার করে। এগুলো প্রতি টোকেনে যতটা প্যারামিটার সক্রিয় করে, তার চেয়ে বেশি মোট প্যারামিটার ধারণ করে, তবে এটি সাধারণ MoE রাউটিংয়ের চেয়ে ভিন্ন পদ্ধতিতে কাজ করে। চারটি মডেলই গ্রাউন্ড আপ মাল্টিমোডাল, অর্থাৎ এরা টেক্সট, ছবি এবং ভিডিও প্রসেস করতে পারে। ছোট দুটি মডেল অডিও ইনপুটও সাপোর্ট করে।
এই লাইনআপে কয়েকটি বিষয় বেশ আকর্ষণীয়। 26B MoE মডেলটি প্রতি টোকেনে মাত্র ৩.৮ বিলিয়ন প্যারামিটার সক্রিয় করে। ২৫.২ বিলিয়ন প্যারামিটার থাকা সত্ত্বেও এর ইনফারেন্স খরচ একটি ৪ বিলিয়ন মডেলের কাছাকাছি। অন্যদিকে E2B হলো এজ (edge) ডিপ্লয়মেন্টের জন্য তৈরি: এর কার্যকরী প্যারামিটার ২.৩ বিলিয়ন, ইনপুট কোয়াড-মোডাল এবং মেমোরি খরচ ১.৫ জিবির নিচে।
সবগুলো মডেলেই ডিকোডার-ওনলি ট্রান্সফরমার আর্কিটেকচার ব্যবহার করা হয়েছে। বড় দুটি মডেলে ২৫৬ হাজার (256K) কনটেক্সট উইন্ডো এবং ছোট দুটিতে ১২৮ হাজার (128K) কনটেক্সট উইন্ডো দেওয়া হয়েছে। কোনো মডেলই শুধু টেক্সট-ভিত্তিক নয়, প্রতিটি ভেরিয়েন্টই নেটিভভাবে ছবি প্রসেস করতে পারে।
Apache 2.0: লাইসেন্স পরিবর্তন কেন এত গুরুত্বপূর্ণ ?
আগের Gemma রিলিজগুলোতে “Gemma Terms of Use” নামক কাস্টম লাইসেন্স ছিল, যা কমার্শিয়াল ব্যবহার, রিডিস্ট্রিবিউশন এবং ডেরিভেটিভ কাজের ওপর বেশ কিছু বিধিনিষেধ আরোপ করেছিল। এই লাইসেন্সের কারণে অনেক টিম গেমা মডেল ব্যবহার করতে গিয়ে দ্বিধায় পড়ত। কিন্তু Apache 2.0 এই সব বাধা দূর করে দিয়েছে। এখন আপনি কোনো বিধিনিষেধ ছাড়াই Gemma 4 কে ফাইন-টিউন করতে পারবেন, কমার্শিয়ালি ডিপ্লয় করতে পারবেন, মডিফায়েড ওয়েটস রিডিস্ট্রিবিউট করতে পারবেন এবং এর ওপর ভিত্তি করে ক্লোজড-সোর্স প্রোডাক্ট তৈরি করতে পারবেন।
এটি Gemma 4-কে আইনি দিক থেকে Llama 4 (যার পারমিসিভ লাইসেন্স আছে কিন্তু ব্যবহারকারীর সংখ্যার লিমিট রয়েছে) এবং Qwen 3.5 (Apache 2.0)-এর সমকক্ষ করে তুলেছে। ইঞ্জিনিয়ারিং টিমগুলোর জন্য ওপেন-ওয়েটস ভিশন মডেল বাছাই করার ক্ষেত্রে লাইসেন্স এখন আর কোনো বাধা নয়। এখন সিদ্ধান্ত নিতে হবে মডেলের ক্ষমতা, কার্যকারিতা এবং ডিপ্লয়মেন্ট সুবিধার ওপর ভিত্তি করে।
২. আর্কিটেকচার: ভিশন টাস্কের জন্য যা যা গুরুত্বপূর্ণ
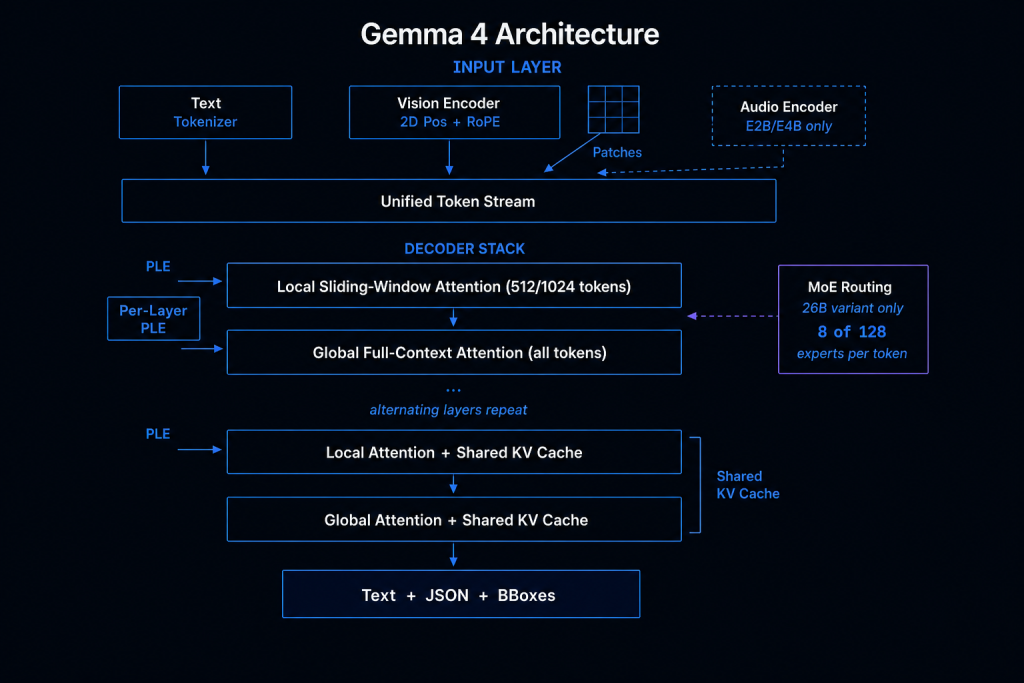
Gemma 4 একটি ডিকোডার-ওনলি ট্রান্সফরমার। এখানে খুব বেশি অভিনবত্ব নেই। তবে আকর্ষণীয় ডিজাইনগুলো মূলত তিনটি জায়গায় রয়েছে: হাইব্রিড অ্যাটেনশন মেকানিজম, ভিশন এনকোডার এবং কনফিগারেবল ইমেজ টোকেন বাজেট। এই প্রতিটি ফিচার কম্পিউটার ভিশন ওয়ার্কলোডে মডেলটি কেমন পারফর্ম করবে তা সরাসরি প্রভাবিত করে।
হাইব্রিড অ্যাটেনশন: স্লাইডিং উইন্ডো + গ্লোবাল
Gemma 4 পর্যায়ক্রমে দুই ধরনের অ্যাটেনশন লেয়ার ব্যবহার করে। লোকাল স্লাইডিং-উইন্ডো লেয়ারগুলো ৫১২ বা ১০২৪ টোকেনের একটি ফিক্সড উইন্ডোতে ফোকাস করে। আর গ্লোবাল ফুল-কনটেক্সট লেয়ারগুলো সিকোয়েন্সের প্রতিটি টোকেনে ফোকাস করে। এই হাইব্রিড পদ্ধতির ফলে মেমোরি খরচ অনেক কমে যায়, কিন্তু মডেলের দীর্ঘ-পরিসরের ডিপেন্ডেন্সি বোঝার ক্ষমতা অটুট থাকে।
মাল্টিপল ছবি বা লম্বা ভিডিও প্রসেস করার ক্ষেত্রে এটি খুব কাজে দেয়। ১ এফপিএস (fps) রেটে একটি ৬০ সেকেন্ডের ভিডিও থেকে ৬০টি ফ্রেম তৈরি হয়। প্রতি ফ্রেমে টোকেন বাজেট বেশি হলে তা খুব দ্রুত মেমোরি শেষ করে দেয়। স্লাইডিং-উইন্ডো লেয়ারগুলো লোকাল প্যাটার্ন (যেমন এজ, টেক্সচার, একটি ফ্রেমের ভেতরের স্পেশিয়াল রিলেশনশিপ) রিকগনিশনের কাজ করে, আর গ্লোবাল লেয়ারগুলো ক্রস-ফ্রেম রিজনিংয়ের কাজ সামলায়।
পার-লেয়ার এম্বেডিংস (PLE)
সাধারণ ট্রান্সফরমারগুলো ইনপুট লেয়ারে প্রতি টোকেনে একটি করে এম্বেডিং তৈরি করে এবং পুরো নেটওয়ার্কে তা পাস করে। কিন্তু Gemma 4 নিয়ে এসেছে পার-লেয়ার এম্বেডিংস: প্রতিটি ডিকোডার লেয়ারে একটি সেকেন্ডারি এম্বেডিং সিগন্যাল ইনজেক্ট করা হয়। এর ফলে প্রতিটি লেয়ার নিজস্ব পজিশনাল এবং সেমান্টিক অ্যাংকর পায়।
এর ব্যবহারিক সুবিধা হলো বেটার গ্রেডিয়েন্ট ফ্লো এবং অনেক বেশি স্ট্যাবল ট্রেনিং, বিশেষ করে 31B মডেলের গভীর লেয়ারগুলোতে। ভিশন টাস্কের ফাইন-টিউনিংয়ের ক্ষেত্রে এটি মডেলের স্পেশিয়াল অ্যাওয়ারনেস ধরে রাখতে সাহায্য করে।
শেয়ারড KV ক্যাশ (Shared KV Cache)
প্রতিটি Gemma 4 মডেলের শেষের দিকের N সংখ্যক লেয়ার নতুন করে KV পেয়ার কম্পিউট করার বদলে আগের লেয়ারের কি-ভ্যালু (key-value) টেনসরগুলো পুনরায় ব্যবহার করে। এটি অ্যাটেনশন প্যাটার্ন পুরোপুরি বাদ না দিয়েই KV ক্যাশ মেমোরি কমিয়ে আনে। সীমিত হার্ডওয়্যারে বড় মডেল চালানোর ক্ষেত্রে মেমোরি সাশ্রয় করার এটি একটি দারুণ ইঞ্জিনিয়ারিং ট্রেড-অফ।
ভিশন এনকোডার : ভ্যারিয়েবল রেজোলিউশন এবং টোকেন বাজেট
Gemma 4-এর ভিশন এনকোডারে লার্নড 2D পজিশনাল এম্বেডিংয়ের সাথে মাল্টিডাইমেনশনাল RoPE ব্যবহার করা হয়েছে। সবচেয়ে বড় ডিজাইন চয়েস হলো: এটি ইনপুট ইমেজের অরিজিনাল অ্যাসপেক্ট রেশিও ধরে রাখে। একটি ১৯২০x১০৮০ স্ক্রিনশট এবং ৬৪০x৬৪০ স্যাটেলাইট ছবি তাদের নিজস্ব আকারেই এনকোড হয়, এদেরকে জোর করে স্কয়ার শেপে রিসাইজ করা হয় না।
সবচেয়ে দারুণ ফিচারটি হলো কনফিগারেবল ইমেজ টোকেন বাজেট। আপনি নির্ধারণ করে দিতে পারবেন প্রতিটি ছবি কতগুলো টোকেন ব্যবহার করবে: ৭০, ১৪০, ২৮০, ৫৬০ নাকি ১১২০ টোকেন। এর মাধ্যমে আপনি ভিজ্যুয়াল ডিটেইল এবং ইনফারেন্স স্পিডের মধ্যে ব্যালেন্স করতে পারবেন।
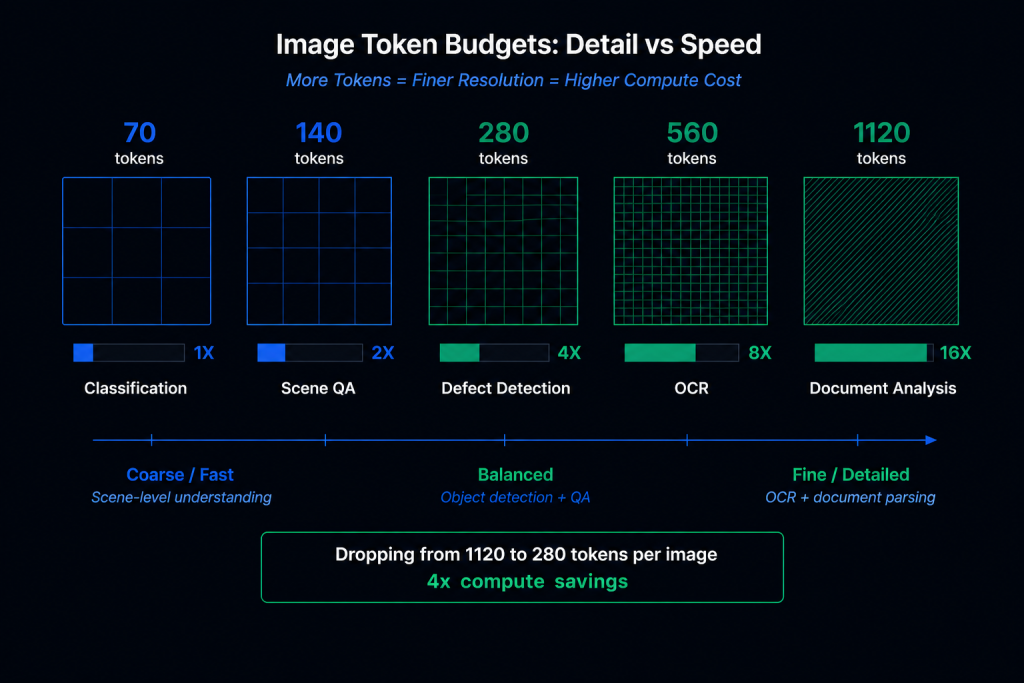
৭০ টোকেনে মডেলটি ছবির একটি রাফ ধারণা পায়, যা সিন ক্লাসিফিকেশনের জন্য যথেষ্ট। ১১২০ টোকেনে এটি এত সূক্ষ্ম ডিটেইল পায় যে তা দিয়ে OCR, ছোট অবজেক্ট ডিটেকশন এবং ডকুমেন্ট লেআউট অ্যানালাইসিস করা সম্ভব। আপনি যদি একটি পাইপলাইনে হাজার হাজার ছবি প্রসেস করেন, তবে ১১২০ টোকেন থেকে কমিয়ে ২৮০ টোকেন ব্যবহার করলে আপনার খরচ চারগুণ কমে যাবে, কিন্তু ডিটেকশনের জন্য পর্যাপ্ত স্পেশিয়াল ইনফরমেশন ঠিকই থাকবে।
৩. ভিশন ক্যাপাবিলিটি: Gemma 4 যা যা করতে পারে
নেটিভ বাউন্ডিং বক্স আউটপুট
Gemma 4 সরাসরি রেসপন্সেই বাউন্ডিং বক্স কোঅর্ডিনেট আউটপুট দিতে পারে। আপনি ছবি দিয়ে ডিটেকশন কোয়েরি করলে এটি স্ট্রাকচারড JSON ফরম্যাটে রেজাল্ট দেবে :
[
{"box_2d": [142, 35, 420, 310], "label": "forklift"},
{"box_2d": [500, 200, 680, 440], "label": "pallet"},
{"box_2d": [60, 310, 195, 490], "label": "safety_cone"}
]এখানে কোঅর্ডিনেট ফরম্যাট হলো [y1, x1, y2, x2], যা TensorFlow অবজেক্ট ডিটেকশন API-এর সাথে মিলে যায় (তবে COCO এবং PyTorch-এর [x1, y1, x2, y2] ফরম্যাট থেকে ভিন্ন)। বিদ্যমান পাইপলাইনে এটি ইন্টিগ্রেট করার সময় বিষয়টি মাথায় রাখতে হবে। এটি ডেডিকেটেড অবজেক্ট ডিটেকশন মডেলের (যেমন YOLOv11) স্পিড বিট করতে পারবে না, কিন্তু এটি আউট-অফ-দ্য-বক্স ওপেন-ভোকাবুলারি ডিটেকশন করতে পারে, যা প্রোটোটাইপিংয়ের জন্য দারুণ কাজ করে।
ভিডিও আন্ডারস্ট্যান্ডিং
চারটি মডেলই ৬০ সেকেন্ড পর্যন্ত ভিডিও ১ ফ্রেম প্রতি সেকেন্ড (fps) রেটে প্রসেস করতে পারে। ২৮০ টোকেন প্রতি ফ্রেম হিসেবে ৬০ ফ্রেমে মোট ১৬,৮০০ টোকেন খরচ হয়, যা সবচেয়ে ছোট E2B ভেরিয়েন্টের ১২৮ হাজার কনটেক্সট উইন্ডোর ভেতরে অনায়াসেই ফিট হয়ে যায়।
OCR এবং ডকুমেন্ট আন্ডারস্ট্যান্ডিং
Gemma 4 অত্যন্ত দক্ষতার সাথে OCR, চার্ট বোঝা, পিডিএফ পড়া এবং GUI এলিমেন্ট ডিটেক্ট করতে পারে। বিশেষ করে 31B মডেলটি ডকুমেন্ট-নির্ভর বেঞ্চমার্কে অনেক ভালো পারফর্ম করে।
৪. এজ ডিপ্লয়মেন্ট: E2B মডেলের গল্প
২০২৬ সালে রিলিজ হওয়া অন্যান্য ওপেন-ওয়েটস VLM থেকে Gemma 4 ঠিক এখানেই আলাদা।
E2B মডেলটি একটি Raspberry Pi 5-এ চলতে পারে। কোনো ক্লাউড জিপিইউ নয়, RTX 4090 পিসিও নয়। মাত্র ৮০ ডলারের ৮ জিবি র্যামের একটি সিঙ্গেল-বোর্ড কম্পিউটারে! গুগল Raspberry Pi 5-এর জন্য নিচের ডেটাগুলো পাবলিশ করেছে:
- প্রিফিল: ১৩৩ টোকেন/সেকেন্ড
- ডিকোড: ৭.৬ টোকেন/সেকেন্ড
- মেমোরি খরচ: ১.৫ জিবির নিচে
এই নম্বরগুলো INT4 কোয়ান্টাইজেশনের ওপর ভিত্তি করে দেওয়া। এটি রিয়েল-টাইম না হলেও কৃষি মনিটরিং, ওয়্যারহাউস ইনভেন্টরি স্ক্যানিং বা কোয়ালিটি চেকের মতো অনেক এজ (edge) ভিশন অ্যাপ্লিকেশনের জন্য ১৫ সেকেন্ডের নিচের রেসপন্স টাইম একদম পারফেক্ট। এটি অ্যান্ড্রয়েড, আইওএস, উইন্ডোজ, লিনাক্স, ম্যাকওএস এবং WebGPU (ব্রাউজারে ইনফারেন্স) সাপোর্ট করে।
৫. প্রতিযোগীদের সাথে তুলনা: Gemma 4 বনাম অন্যান্য মডেল
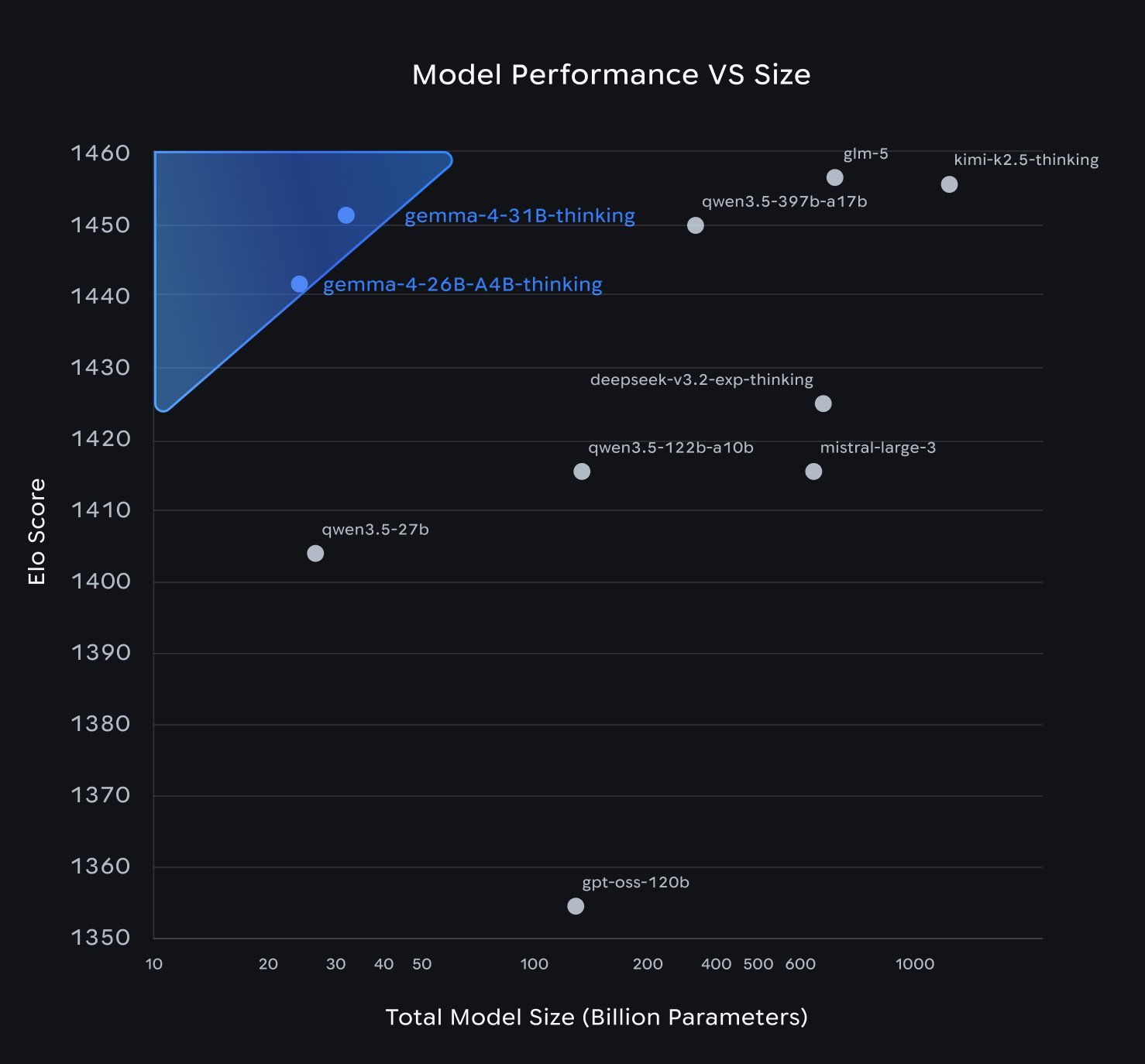
Gemma 4 31B বনাম Qwen 3.5 27B এই দুটি মডেলই “লার্জ ওপেন-ওয়েটস VLM” ক্যাটাগরিতে একে অপরের সবচেয়ে কাছের প্রতিযোগী।
- GPQA Diamond: প্রায় টাই (সমান)।
- MMMU Pro: Gemma 4 31B এগিয়ে আছে (৭৬.৯%)।
- এজ ডিপ্লয়মেন্ট: Qwen 3.5-এর সবচেয়ে ছোট মডেল 0.8B। অন্যদিকে Gemma 4 E2B এর কার্যকরী প্যারামিটার ২.৩ বিলিয়ন এবং এটি Raspberry Pi-তে চলে, যা অনেক বেশি প্র্যাক্টিক্যাল।
- লাইসেন্স: উভয়েই Apache 2.0।
Gemma 4 বনাম Llama 4 Scout মেটার Llama 4 Scout একটি 17B অ্যাক্টিভ প্যারামিটারের MoE মডেল, যা মাল্টি-ইমেজ এবং লং-কনটেক্সটে ভালো। তবে Gemma 4-এর 26B MoE (৩.৮ বিলিয়ন অ্যাক্টিভ) কম্পিউট খরচের দিক থেকে অনেক ছোট, ফলে মেমোরি এবং ল্যাটেন্সিতে এটি এগিয়ে থাকে।

কোথায় Gemma 4 বিজয়ী:
- এজ ডিপ্লয়মেন্ট (E2B এর সমকক্ষ এই সাইজে কেউ নেই)।
- প্ল্যাটফর্ম কভারেজ।
- পারমিসিভ লাইসেন্স।
- কনফিগারেবল ইমেজ টোকেন বাজেট।
- নেটিভ বাউন্ডিং বক্স আউটপুট।
কোথায় Gemma 4 পিছিয়ে:
- পিক বেঞ্চমার্ক স্কোর (GLM-5 এবং Qwen 3.5 কিছু জায়গায় এগিয়ে)।
- সর্বোচ্চ কনটেক্সট লেন্থ (২৫৬ হাজার বনাম Qwen-এর ১ মিলিয়ন)।
- ডকুমেন্টেশনের অভাব (এখনো কোনো রিসার্চ পেপার নেই)।
৬. ভিশন টাস্কের জন্য ফাইন-টিউনিং
Apache 2.0 লাইসেন্স থাকার ফলে আপনি সহজেই Gemma 4 ফাইন-টিউন করে কমার্শিয়ালি ডিপ্লয় করতে পারবেন। এজ ডিপ্লয়মেন্ট টার্গেট হলে E4B (৪.৫ বিলিয়ন কার্যকরী প্যারামিটার) দিয়ে শুরু করতে পারেন। এটি একটি কনজ্যুমার জিপিইউতে LoRA বা QLoRA দিয়ে ফাইন-টিউন করার জন্য একদম পারফেক্ট।
সার্ভার-সাইড ডিপ্লয়মেন্টের জন্য 26B MoE হলো সবচেয়ে সেরা অপশন। এটি 31B-এর কাছাকাছি অ্যাকুরেসি দেয় কিন্তু ইনফারেন্স খরচ অনেক কম। ডেটাসেট ফরম্যাট হিসেবে ইমেজ এবং [y1, x1, y2, x2] কোঅর্ডিনেট ব্যবহার করে জেসন (JSON) ফরম্যাটের বাউন্ডিং বক্স টার্গেট দিন। মনে রাখবেন, ট্রেনিং এবং ইনফারেন্সের সময় টোকেন বাজেট যেন সমান থাকে।
৭. Datature Vi: রোডম্যাপে Gemma 4
Datature-এর Vi প্ল্যাটফর্ম খুব শীঘ্রই Gemma 4 সাপোর্ট করবে। Vi ক্রেডিট-ভিত্তিক প্রাইসিং মডেলে কাজ করে এবং Gemma 4-এর বিভিন্ন সাইজের ভেরিয়েন্ট ইউজারদেরকে কস্ট-অ্যাকুরেসি স্পেকট্রামে অনেক অপশন দেবে।
৮. সিভি (CV) ইঞ্জিনিয়ারদের জন্য এর অর্থ কী ?
Gemma 4 কম্পিউটার ভিশনের সব নিয়ম পাল্টে দেয়নি, কিন্তু এটি একসাথে বেশ কিছু সীমানা অতিক্রম করেছে। এজ ভিশন এখন একটি সত্যিকার ওপেন-ওয়েটস অপশন পেয়েছে। কনফিগারেবল টোকেন বাজেট প্রোডাকশন পাইপলাইনে একটি গেম-চেঞ্জার। তবে রিসার্চ পেপার না থাকায় সেফটি ইভ্যালুয়েশন এবং কনটেন্ট ফিল্টারিংয়ের বিষয়টা নিজেদেরই টেস্ট করে নিতে হবে।
সাধারণ জিজ্ঞাসা (FAQ)
Gemma 4 এবং Gemini 4 এর মধ্যে পার্থক্য কী ?
Gemma 4 হলো গুগলের ওপেন-ওয়েটস মডেল ফ্যামিলি, যা Apache 2.0 লাইসেন্সের অধীনে রিলিজ হয়েছে। এটি ডাউনলোড এবং কমার্শিয়ালি ব্যবহার করা যায়। অন্যদিকে Gemini হলো গুগলের প্রোপাইটারি API মডেল, যা কেবল তাদের API-এর মাধ্যমেই ব্যবহারযোগ্য।
Gemma 4 কি YOLO-এর মতো ডেডিকেটেড অবজেক্ট ডিটেকশন মডেলকে রিপ্লেস করতে পারে ?
হাই-থ্রুপুট প্রোডাকশনের ক্ষেত্রে না। ফিক্সড-ক্লাস ডিটেকশনে একটি ফাইন-টিউনড YOLO মডেল ১০ থেকে ১০০ গুণ বেশি ফাস্ট হবে। তবে জিরো-শট এবং ওপেন-ভোকাবুলারি ডিটেকশনের জন্য Gemma 4 দারুণ কাজ করে।
এজ ডিপ্লয়মেন্টের জন্য কোন Gemma 4 মডেলটি ব্যবহার করব ?
Raspberry Pi, ফোন বা লো-পাওয়ার ডিভাইস হলে E2B (২.৩ বিলিয়ন ইফেক্টিভ প্যারামিটার) দিয়ে শুরু করুন। একটু ভালো ল্যাপটপ বা ট্যাবলেট হলে E4B ব্যবহার করতে পারেন।
কম্পিউটার ভিশনের জন্য কি Qwen 3.5-এর চেয়ে Gemma 4 ভালো ?
এটি ডিপ্লয়মেন্ট টার্গেটের ওপর নির্ভর করে। ক্লাউড ইনফারেন্সে সর্বোচ্চ অ্যাকুরেসির জন্য Qwen 3.5 কিছুটা এগিয়ে। তবে অন-ডিভাইস বা ব্রাউজার-ভিত্তিক ভিশন এবং এজ ডিপ্লয়মেন্টের ক্ষেত্রে Gemma 4 নিঃসন্দেহে বিজয়ী।
Gemma 4 কি ভিডিও ইনপুট সাপোর্ট করে ?
হ্যাঁ। চারটি মডেলই ৬০ সেকেন্ড পর্যন্ত ভিডিও (১ fps রেটে) প্রসেস করতে পারে। ছোট দুটি মডেল (E2B এবং E4B) ছবি ও ভিডিওর পাশাপাশি অডিও ইনপুটও সাপোর্ট করে।


